Funktionen
Duckling bietet umfassende Funktionen für die Dokumentkonvertierung.
Dokumenten-Upload
Drag-and-drop
Ziehen Sie Dateien auf die Ablagezone für den sofortigen Upload. Die Oberfläche prüft Dateitypen und zeigt den Upload-Fortschritt.
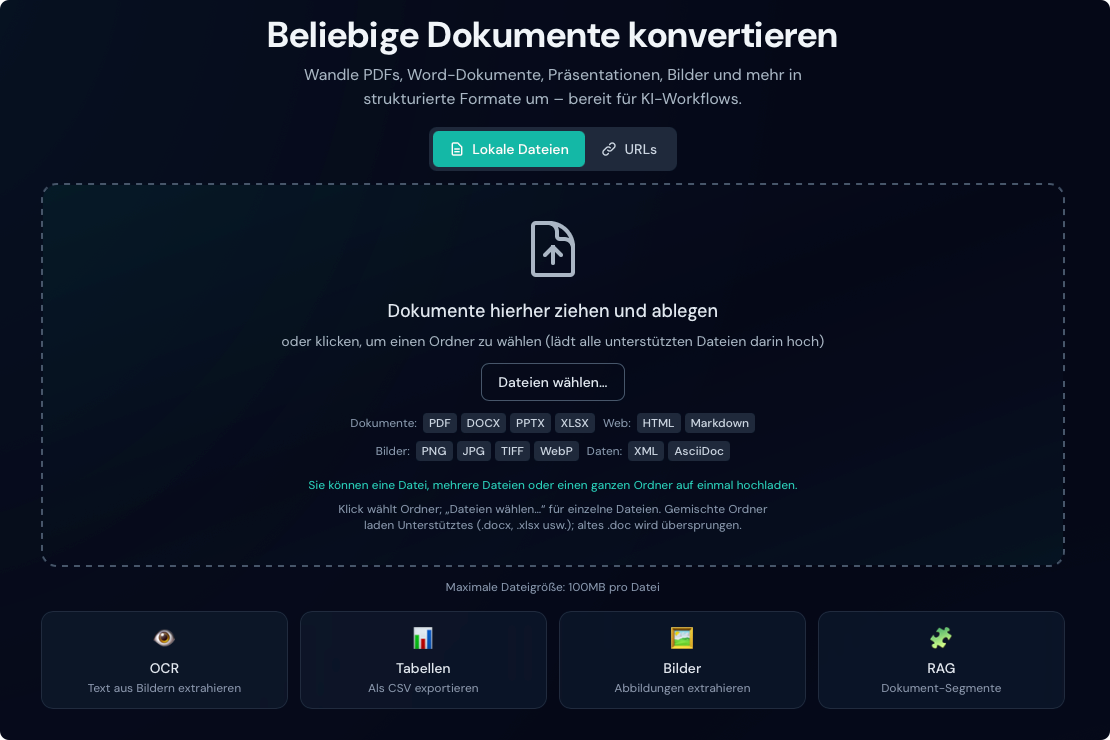
Eingabe per URL
Konvertieren Sie Dokumente direkt über URLs, ohne sie zuerst manuell herunterzuladen:
- Klicken Sie auf die Registerkarte URLs über der Ablagezone
- Fügen Sie eine URL pro Zeile ein (eine Zeile = ein Dokument; mehrere Zeilen = Stapelverarbeitung)
- Klicken Sie auf Alle konvertieren
- Die Dokumente werden automatisch heruntergeladen und konvertiert
Unterstützte URL-Funktionen:
- Automatische Erkennung des Dateityps aus dem URL-Pfad
- Erkennung per
Content-Type-Header bei Dateien ohne Erweiterung - Unterstützung von
Content-Dispositionfür Dateinamen - Dieselben Typbeschränkungen wie bei lokalen Uploads
- Automatischer Bild-Export für HTML-Seiten: Beim Konvertieren von HTML über URLs lädt Duckling alle in der Seite referenzierten Bilder herunter und stellt sie in der Bildvorschau-Galerie bereit
HTML-Seiten mit Bildern
Wenn Sie eine HTML-Seite konvertieren (z. B. einen Blogartikel), führt Duckling Folgendes aus:
- Lädt den HTML-Inhalt herunter
- Findet alle
<img>-Tags und CSS-Hintergrundbilder - Lädt jedes Bild von seiner Quell-URL herunter
- Bettet die Bilder als Base64-Daten-URIs in das HTML ein
- Speichert die Bilder separat für Vorschau und Download
So bleiben alle Bilder in den konvertierten HTML-Dokumenten erhalten, auch offline.
Direkte Links
Verwenden Sie direkte Download-Links, keine generischen Webseiten-URLs. Zum Beispiel:
- ✅
https://example.com/document.pdf - ✅
https://example.com/blog/article(HTML-Seiten funktionieren ebenfalls) - ❌
https://example.com/view/document(per JavaScript gerenderte Inhalte funktionieren ggf. nicht)
Mehrere Dateien und Ordner
Laden Sie mehrere Dateien (oder einen ganzen Ordner) über dieselbe Zone hoch – ohne separaten Modus:
- Dateien ziehen, Ordner wählen oder Dateien wählen… nutzen
- Zur Registerkarte URLs wechseln und eine URL pro Zeile einfügen
- Den Fortschritt verfolgen (ein Auftrag: übliche Ansicht; mehrere: Mehrdatei-Übersicht)
- Ergebnisse einzeln oder gesamt nach dem Stapel herunterladen
Mehrere URLs
Das URL-Feld ist immer ein mehrzeiliges Textfeld:
- Zur Registerkarte URLs wechseln
- Eine URL pro Zeile einfügen
- Auf Alle konvertieren klicken
Gleichzeitige Verarbeitung
Die Warteschlange verarbeitet bis zu 2 Dokumente parallel, um den Speicherverbrauch zu begrenzen.
OCR (optische Zeichenerkennung)
Text aus gescannten Dokumenten und Bildern extrahieren.
Unterstützte Engines
| Engine | Beschreibung | GPU | Ideal für |
|---|---|---|---|
| EasyOCR | Mehrsprachig, präzise | Ja (CUDA) | Komplexe Dokumente |
| Tesseract | Klassisch, zuverlässig | Nein | Einfache Dokumente |
| macOS Vision | Native Apple-OCR | Apple Neural Engine | Mac-Nutzer |
| RapidOCR | Schnell, schlank | Nein | Hoher Durchsatz |
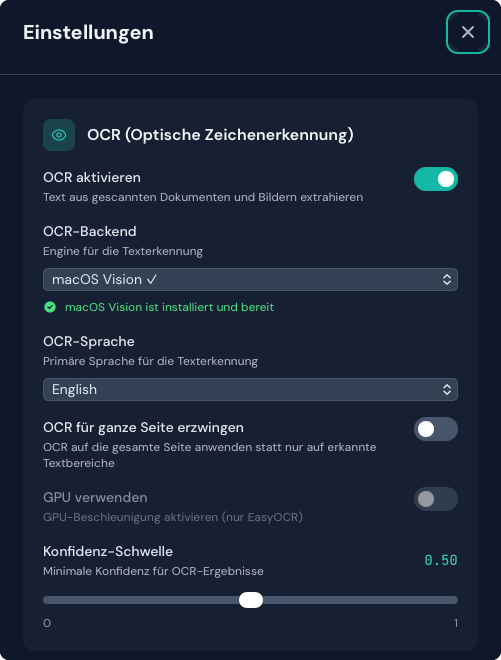
Automatische Installation der Engines
Duckling kann OCR-Engines bei Auswahl automatisch installieren:
- Öffnen Sie das Panel Einstellungen
- Wählen Sie eine OCR-Engine in der Liste
- Ist sie nicht installiert, erscheint Installieren
- Klicken Sie für die Installation per pip
Installationsvoraussetzungen
- EasyOCR, OcrMac, RapidOCR: Installation per pip möglich
- Tesseract: zuerst systemweit installieren:
- macOS:
brew install tesseract - Ubuntu/Debian:
apt-get install tesseract-ocr - Windows: Download von GitHub releases
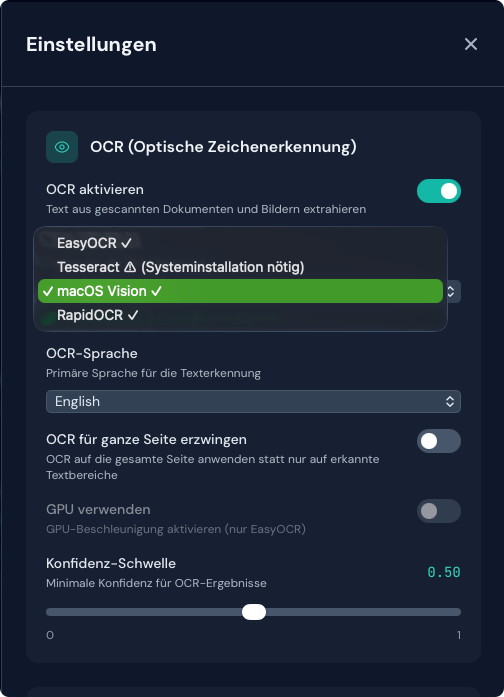
Das Panel Einstellungen zeigt den Status jeder Engine:
- ✓ Installiert und bereit – für die Konvertierung verfügbar
- ⚠ Nicht installiert – zum Installieren klicken (per pip installierbar)
- ℹ Systeminstallation erforderlich – manuelle Anleitung befolgen
Unterstützte Sprachen
Über 28 Sprachen, u. a.:
- Europa: Englisch, Deutsch, Französisch, Spanisch, Italienisch, Portugiesisch, Niederländisch, Polnisch, Russisch
- Asien: Japanisch, Chinesisch (vereinfacht/traditionell), Koreanisch, Thai, Vietnamesisch
- Naher Osten: Arabisch, Hebräisch, Türkisch
- Südasien: Hindi
OCR-Optionen
| Option | Beschreibung |
|---|---|
| Gesamte Seite per OCR | Ganze Seite statt nur erkannte Bereiche |
| GPU-Beschleunigung | CUDA für schnellere Verarbeitung (EasyOCR) |
| Konfidenzschwelle | Mindest-Konfidenz der Ergebnisse (0–1) |
| Bitmap-Flächenschwelle | Mindestflächenanteil für Bitmap-OCR |
Tabellenextraktion
Tabellen in Dokumenten automatisch erkennen und extrahieren.
Erkennungsmodi
- Präzisere Erkennung
- Bessere Zellgrenzen
- Langsamere Verarbeitung
- Empfohlen für komplexe Tabellen
- Schnellere Verarbeitung
- Gut für einfache Tabellen
- Komplexe Strukturen können fehlen
Exportoptionen
- CSV: jede Tabelle als CSV herunterladen
- Bild: Tabelle als PNG herunterladen
- JSON: vollständige Tabellenstruktur in der API-Antwort
Bildextraktion
Eingebettete Bilder aus Dokumenten extrahieren.
Optionen
| Option | Beschreibung |
|---|---|
| Bilder extrahieren | Bildextraktion aktivieren |
| Bilder klassifizieren | Bilder taggen (Abbildung, Grafik usw.) |
| Seitenbilder erzeugen | Pro Seite ein Bild erzeugen |
| Abbildungsbilder erzeugen | Abbildungen als Dateien extrahieren |
| Tabellenbilder erzeugen | Tabellen als Bilder extrahieren |
| Bildskala | Ausgabeskalierung (0,1x bis 4,0x) |
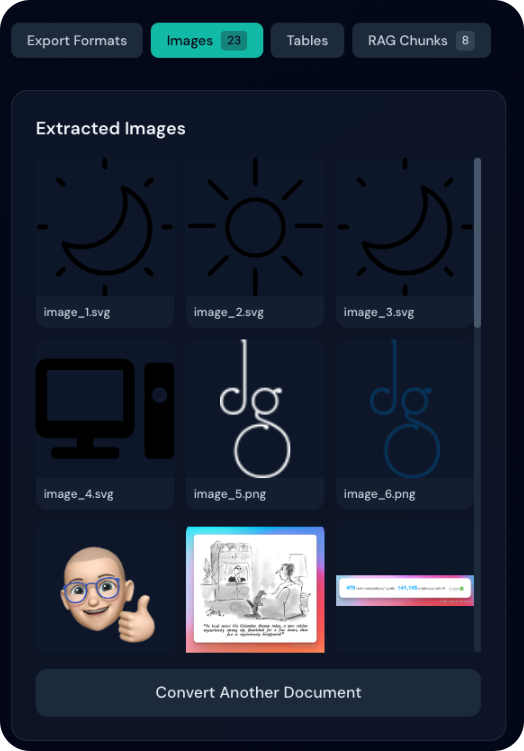
Bildvorschau-Galerie
Nach der Konvertierung erscheinen extrahierte Bilder in einer Galerie:
- Miniaturraster: alle Bilder als Vorschaubilder
- Aktionen beim Hover: schneller Zugriff auf Anzeige und Download
- Lightbox: Klick für Vollbild in einem Dialog
- Navigation: Pfeile zum Durchblättern
- Herunterladen: einzeln aus Galerie oder Lightbox

Bildformate
Extrahierte Bilder werden als PNG gespeichert für maximale Kompatibilität.
Dokumenten-Anreicherung
Erweitern Sie konvertierte Dokumente mit KI-gestützten Funktionen.
Verfügbare Anreicherungen
| Funktion | Beschreibung | Auswirkung |
|---|---|---|
| Code-Anreicherung | Spracherkennung und verbesserte Codeblöcke | Gering |
| Formel-Anreicherung | LaTeX aus mathematischen Gleichungen | Mittel |
| Bildklassifikation | Semantische Typen (Abbildung, Diagramm, Foto) | Gering |
| Bildbeschreibung | KI-generierte Bildunterschriften | Hoch |
Konfiguration
Aktivieren Sie Anreicherungen unter Einstellungen, Abschnitt Dokumenten-Anreicherung:
- Einstellungen öffnen (Zahnrad)
- Zu Dokumenten-Anreicherung scrollen
- Gewünschte Optionen ein-/ausschalten
- Einstellungen werden automatisch gespeichert
Verarbeitungsdauer
Anreicherungen, besonders Bildbeschreibung und Formel-Anreicherung, verlängern die Laufzeit deutlich (Modell-Inferenz). Bei Aktivierung erscheint ein Hinweis.
Code-Anreicherung
Aktiviert u. a.:
- Automatische Programmiersprachen-Erkennung
- Metadaten für Syntaxhervorhebung
- Bessere Strukturerkennung von Code
Formel-Anreicherung
Extrahiert mathematische Formeln und wandelt sie in LaTeX um:
- Inline:
$E = mc^2$ - Abgesetzte Gleichungen mit Formatierung
- Besseres Rendering in HTML- und Markdown-Export
Bildklassifikation
Versieht Bilder mit Typ-Tags:
- Abbildung: Schemata, Illustrationen
- Diagramm: Balken, Linien, Kreise
- Foto: Fotos, Screenshots
- Logo: Logos, Symbole
- Tabelle: Tabellenbilder (getrennt von Tabellenextraktion)
Bildbeschreibung
Nutzt Vision-Sprach-Modelle für Beschreibungen:
- Beschreibungen in natürlicher Sprache
- Hilfreich für Barrierefreiheit (Alternativtext)
- Bessere Durchsuchbarkeit
- Modell-Download beim ersten Einsatz
Modellanforderungen
Bildbeschreibung benötigt ein Vision-Sprach-Modell (~1–2 GB), automatischer Download beim ersten Einsatz (kann mehrere Minuten dauern).
Modelle vorab herunterladen
Um Wartezeiten zu vermeiden, können Sie Modelle vorab laden:
- Einstellungen öffnen
- Zu Dokumenten-Anreicherung scrollen
- Unten den Bereich Modelle vorab herunterladen nutzen
- Neben dem gewünschten Modell auf Herunterladen klicken
| Modell | Größe | Zweck |
|---|---|---|
| Bildklassifikator | ~350 MB | Bildtyp |
| Bildbeschreiber | ~2 GB | KI-Bildtexte |
| Formelerkenner | ~500 MB | LaTeX-Extraktion |
| Code-Erkenner | ~200 MB | Programmiersprache |
Download-Fortschritt
Ein Fortschrittsbalken zeigt den Status. Modelle werden lokal gecacht; einmaliger Download genügt.
RAG-Segmentierung
Erzeugen Sie Dokumentsegmente für Retrieval-Augmented Generation (RAG).
Funktionsweise
- Das Dokument wird in semantische Segmente zerlegt
- Jedes Segment respektiert die Dokumentstruktur
- Segmente enthalten Metadaten (Überschriften, Seitenzahlen)
- Zu kleine Segmente können zusammengeführt werden
Konfiguration
| Parameter | Beschreibung | Standard |
|---|---|---|
| Max. Token | Maximale Token pro Segment | 512 |
| Peers zusammenführen | Kleine Segmente zusammenführen | true |
Ausgabeformat
{
"chunks": [
{
"id": 1,
"text": "Introduction to machine learning...",
"meta": {
"headings": ["Chapter 1", "Introduction"],
"page": 1
}
}
]
}
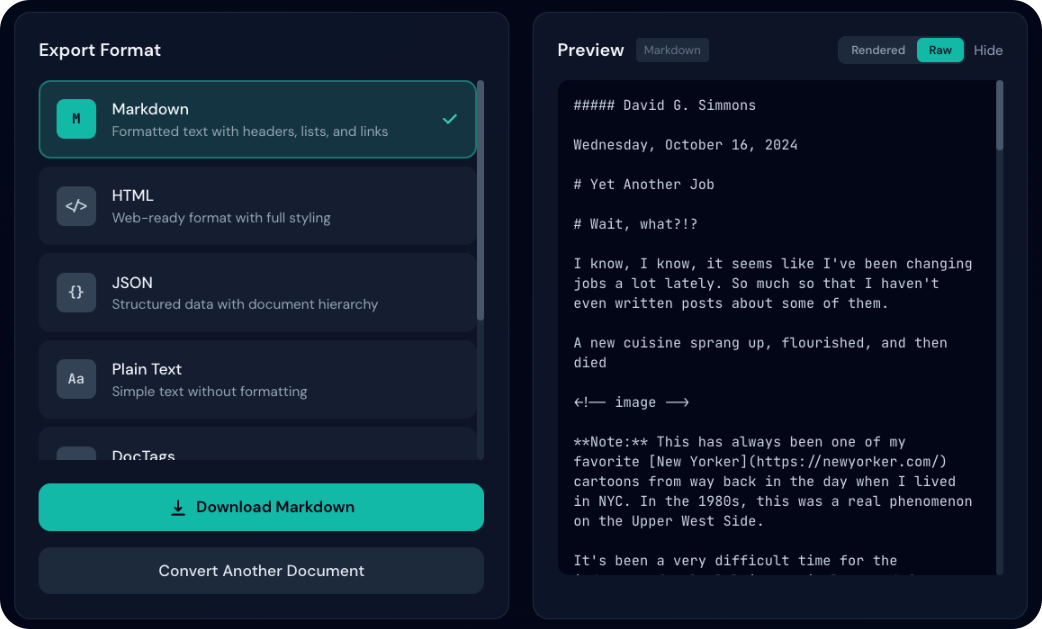
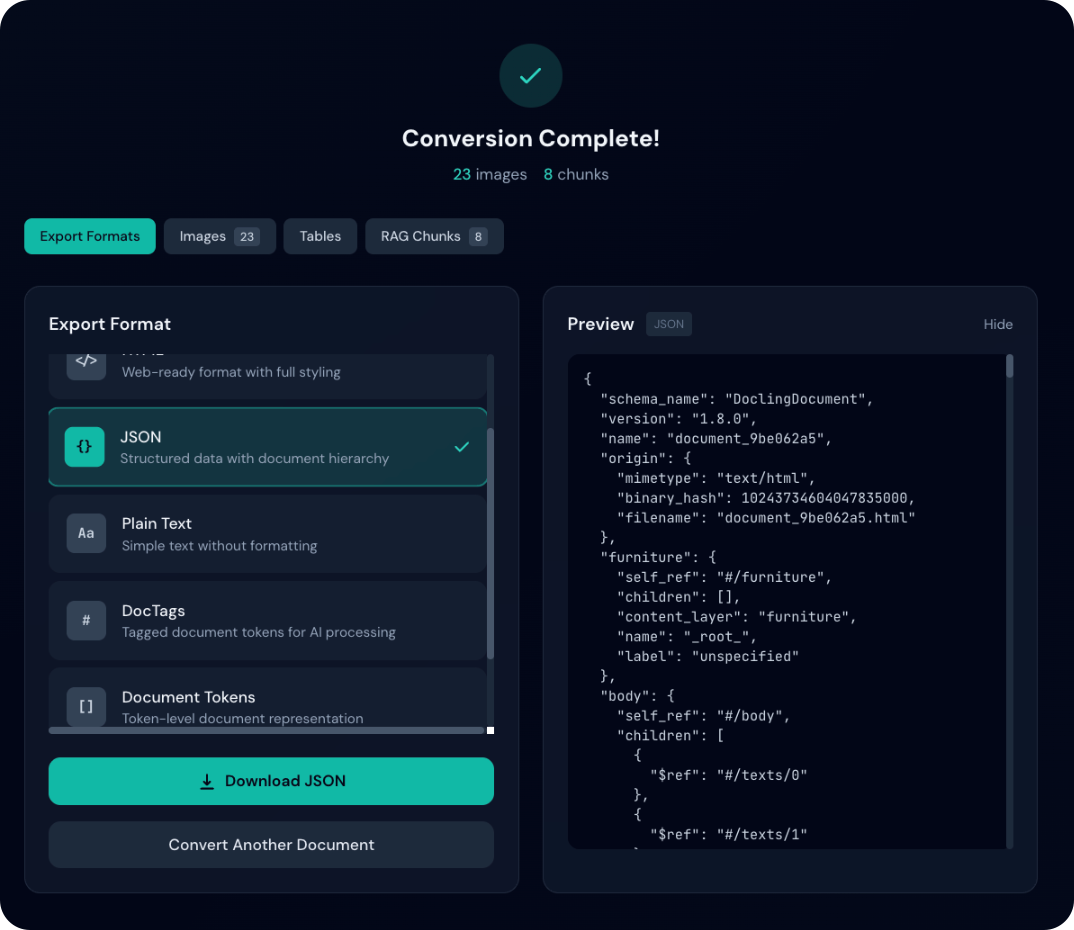
Exportformate
Verfügbare Formate
| Format | Erweiterung | Beschreibung |
|---|---|---|
| Markdown | .md | Strukturierter Text (Überschriften, Listen, Links) |
| HTML | .html | Webfertig mit Styling |
| JSON | .json | Vollständige Dokumentstruktur (verlustfrei) |
| Klartext | .txt | Einfacher Text |
| DocTags | .doctags | Getaggtes Format |
| Document Tokens | .tokens.json | Token-Ebene |
| RAG-Chunks | .chunks.json | Segmente für RAG-Anwendungen |
Vorschau
Das Export-Panel zeigt eine Live-Vorschau, die sich mit dem gewählten Format aktualisiert.
Vorschau pro Format
- Dynamischer Inhalt: lädt je nach gewähltem Format
- Format-Badge: aktuell angezeigtes Format
- Zwischenspeicher: schnelles Umschalten bereits geladener Formate
Gerendert oder Roh
Bei HTML und Markdown zwischen gerendertem und Quelltext umschalten:

- HTML: Formatierung, Tabellen, Links
- Markdown: Überschriften, fett/kursiv, Codeblöcke, Links
- Ideal für die visuelle Prüfung
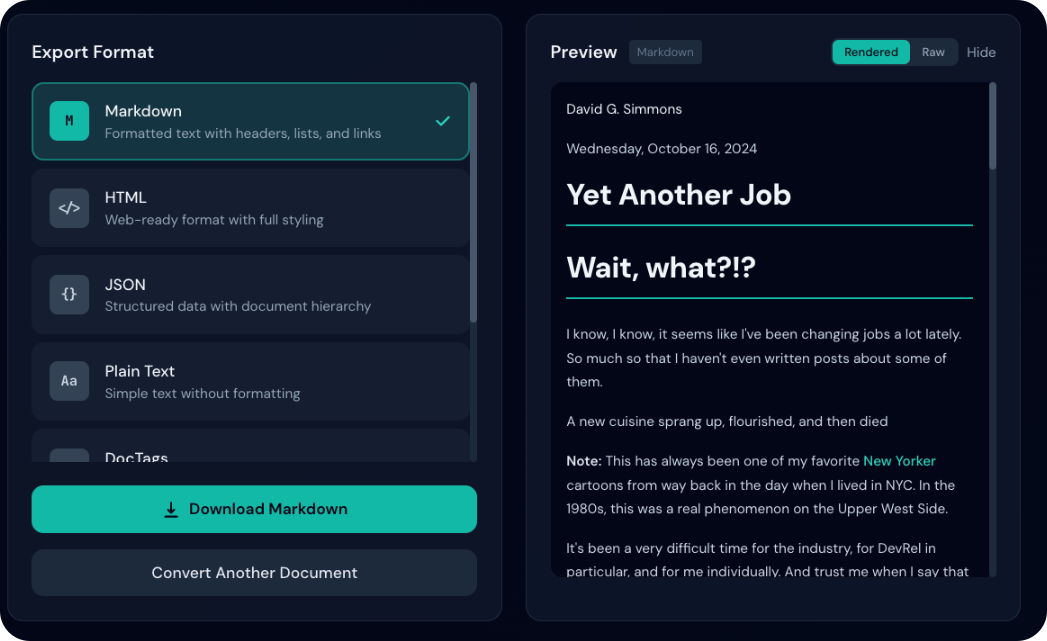
- Zeigt den Quellcode
- HTML: Roh-Tags und Attribute
- Markdown: Syntax (
#,**fett**, usw.) - Nützlich zum Kopieren oder für Format-Debugging
Weitere Formate
- JSON: formatiert mit Einrückung
- Klartext: unverändert
- DocTags / Tokens: Rohanzeige
Konvertierungsverlauf
Zugriff auf zuvor konvertierte Dokumente:
- Status und Metadaten der Konvertierung
- Erneuter Download der Ergebnisse
- Suche nach Dateinamen
- Konvertierungsstatistiken
Funktionen des Verlaufs
- Suche: nach Dateinamen
- Filter: nach Status (abgeschlossen, fehlgeschlagen)
- Export: Verlauf als JSON
- Dokument erneut laden: abgeschlossene Einträge anklicken, Ergebnis ohne Neukonvertierung öffnen
- Dokumente werden nach der Konvertierung auf der Festplatte gespeichert
- Vollständige Struktur bleibt erhalten; sofortiges erneutes Laden
- Deduplizierung: gleiche Datei und gleiche Einstellungen nutzen gespeicherte Ausgabe
- Chunks jetzt erzeugen: fehlen RAG-Segmente, Erzeugung auf Abruf mit aktuellen Chunking-Einstellungen (ohne Neukonvertierung)
- Konvertierungen mit gleichem Inhalt und dokumentrelevanten Einstellungen (OCR, Tabellen, Bilder) können aus dem Cache kommen
- Ausgaben werden einmal gespeichert und per Symlinks geteilt
Statistik-Panel
Seitenpanel für Konvertierungsanalysen. Öffnen über Statistiken in der Kopfzeile oder Vollständige Statistiken anzeigen im Verlauf.
Überblick
- Gesamtzahl Konvertierungen, Erfolg/Fehler, Erfolgsquote
- Mittlere Bearbeitungszeit und Warteschlangen-Tiefe
Speicher
- Uploads, Ausgaben und Gesamtspeicher
Aufschlüsselungen
- Eingabeformate, OCR-Engines, Ausgabeformate
- Hardware (CPU/CUDA/MPS), Quelltypen
- Fehlerkategorien
- Anzahl mit aktivem RAG-Chunking
Erweiterte Metriken
- System: Hardware-Typ (CPU/CUDA/MPS), CPU-Kerne, aktuelle CPU-Last (Duckling-Backend), GPU-Infos
- Durchsatz: durchschnittliche Seiten/s und Seiten/s pro CPU-Kern
- Zeitverteilung: Median, 95. und 99. Perzentil
- Seiten/s über die Zeit: Diagramm im Verlauf
- Leistung nach Konfiguration: Seiten/s und Dauer nach Hardware, OCR-Engine und Bildklassifikator